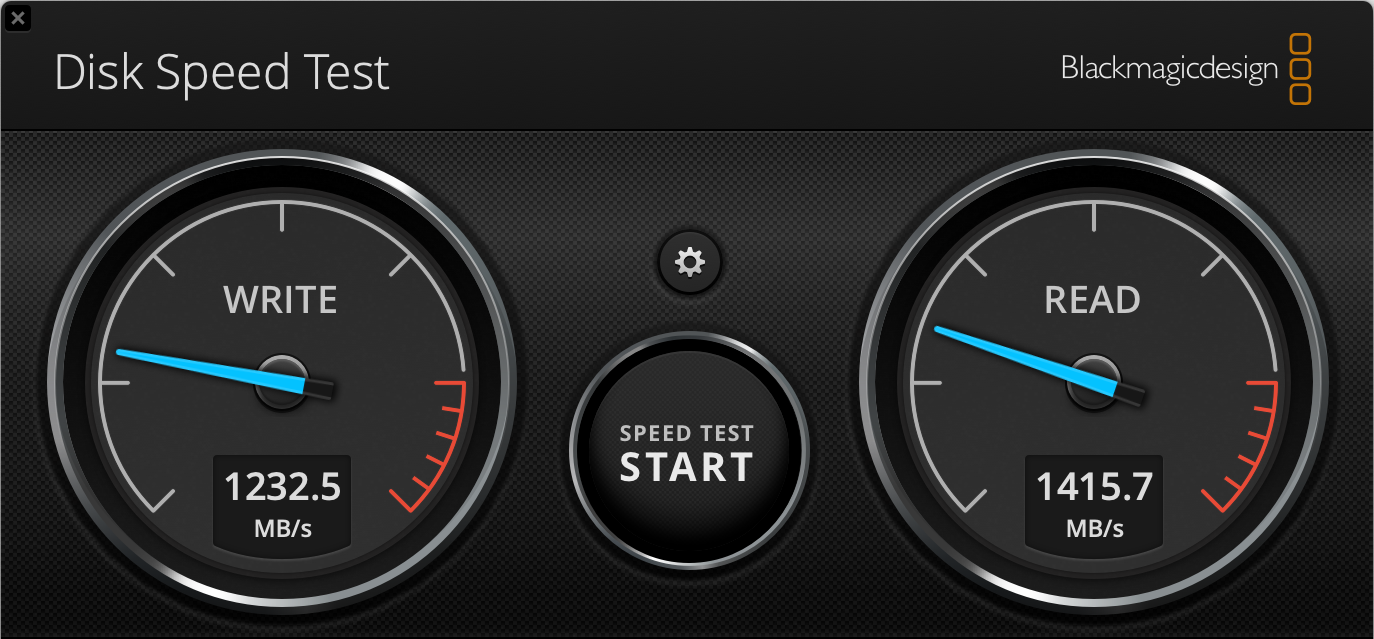
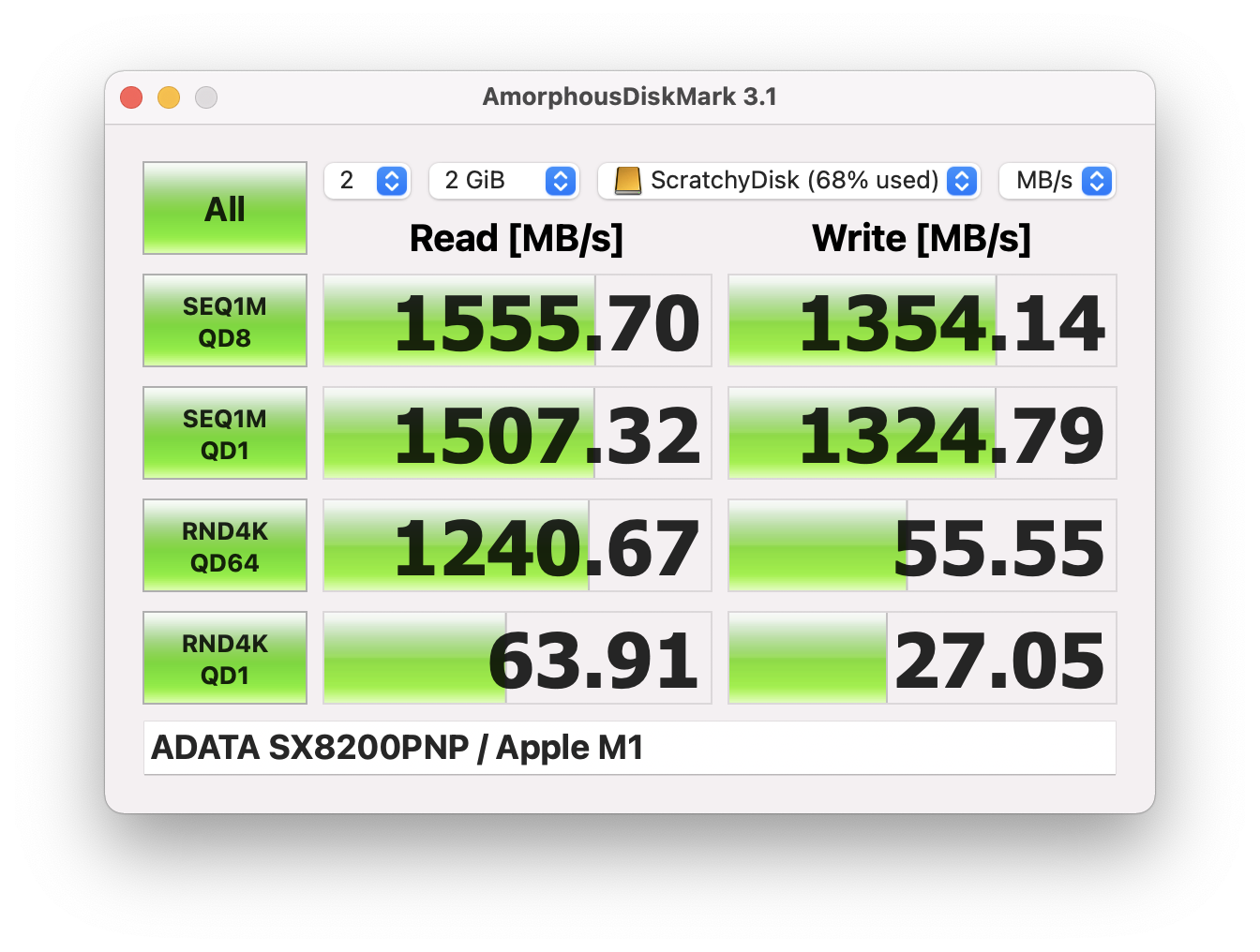
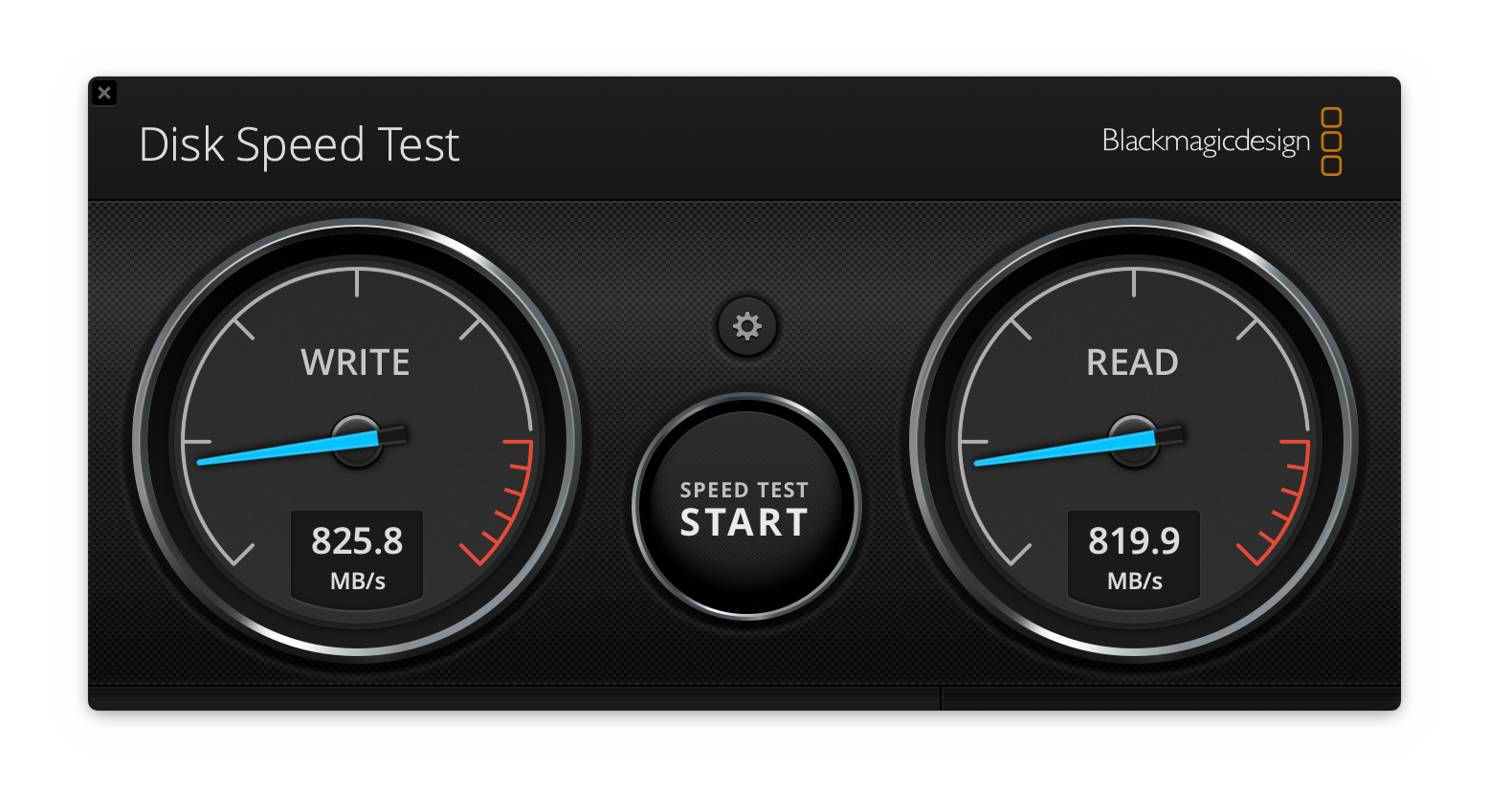
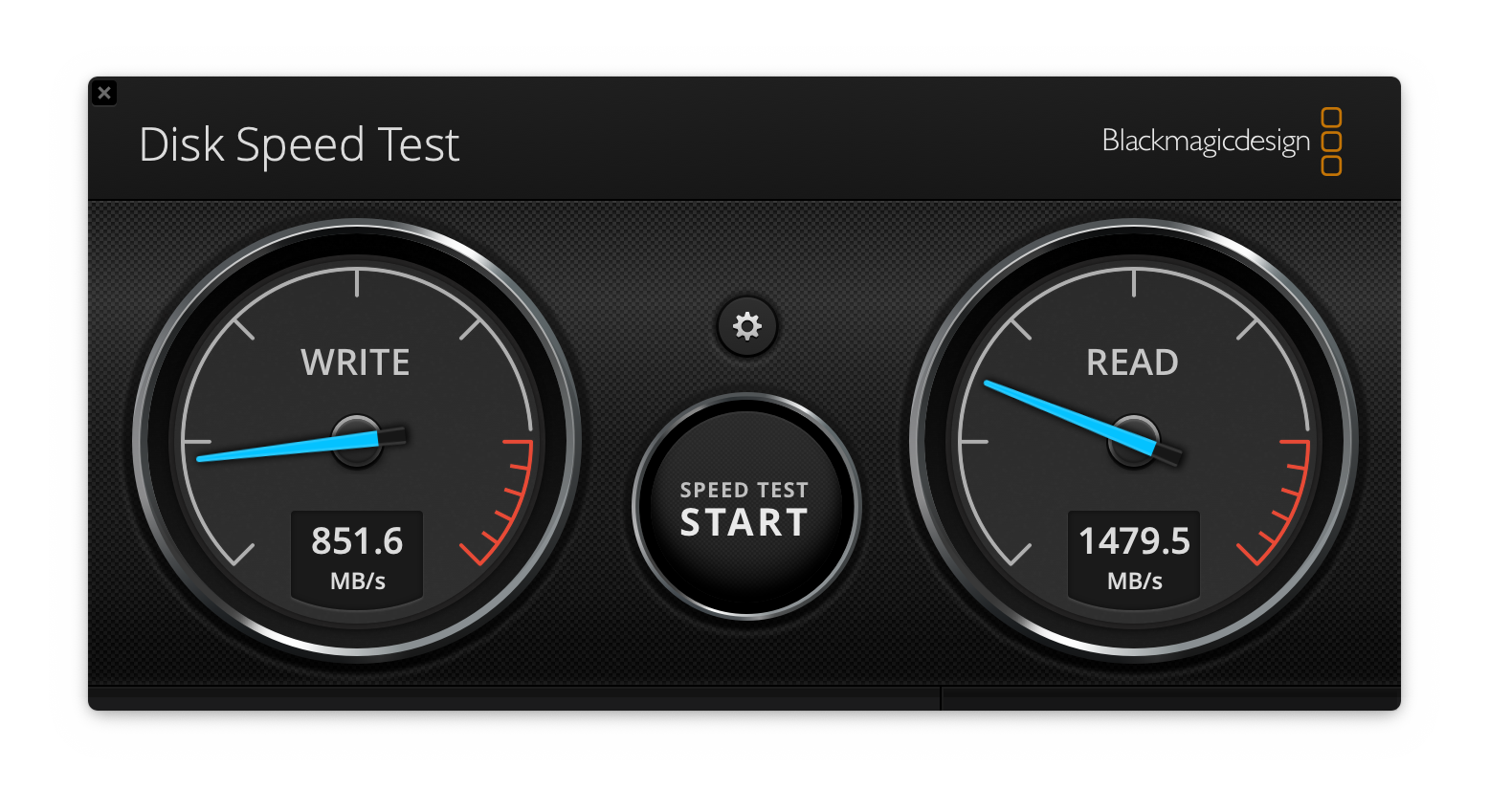
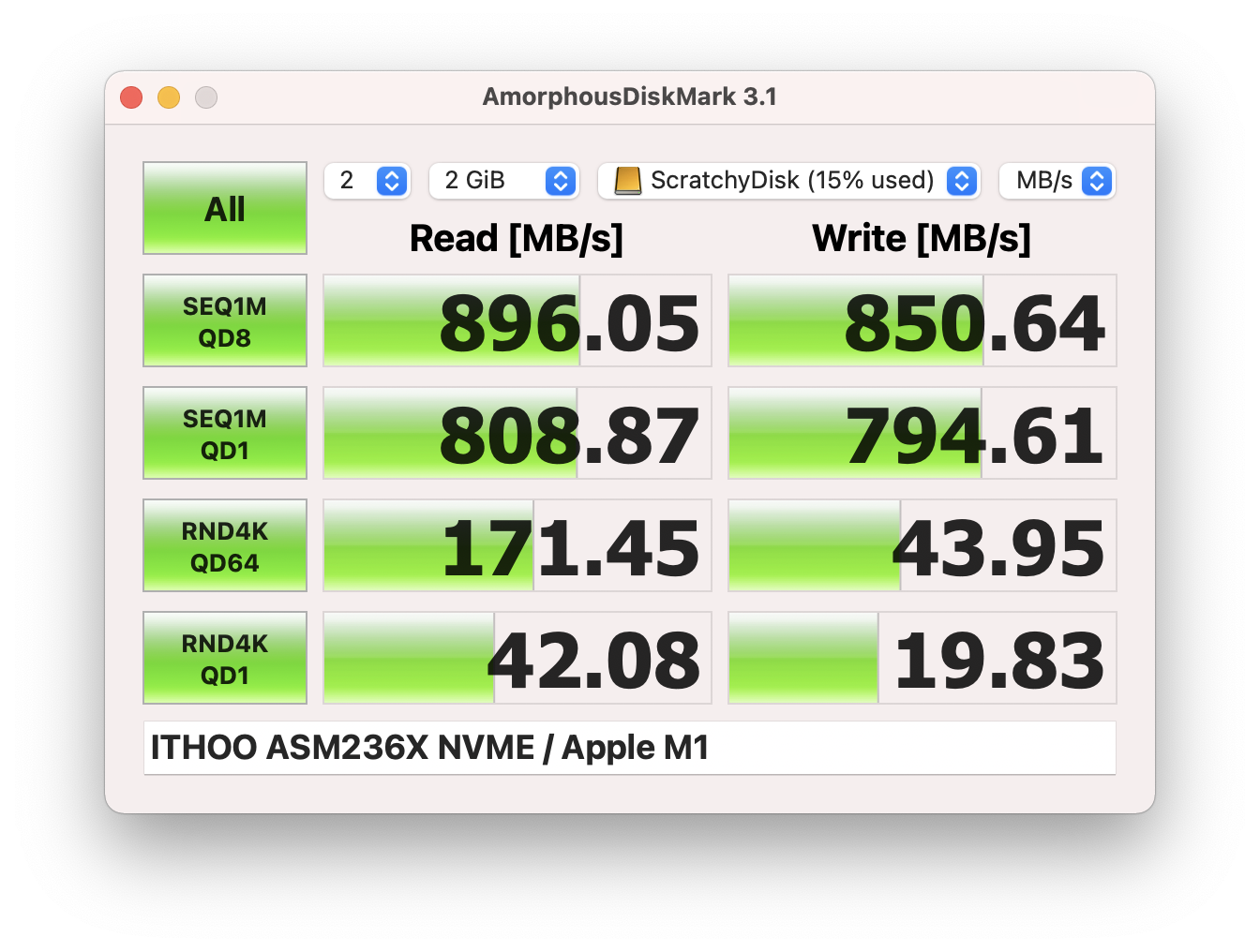
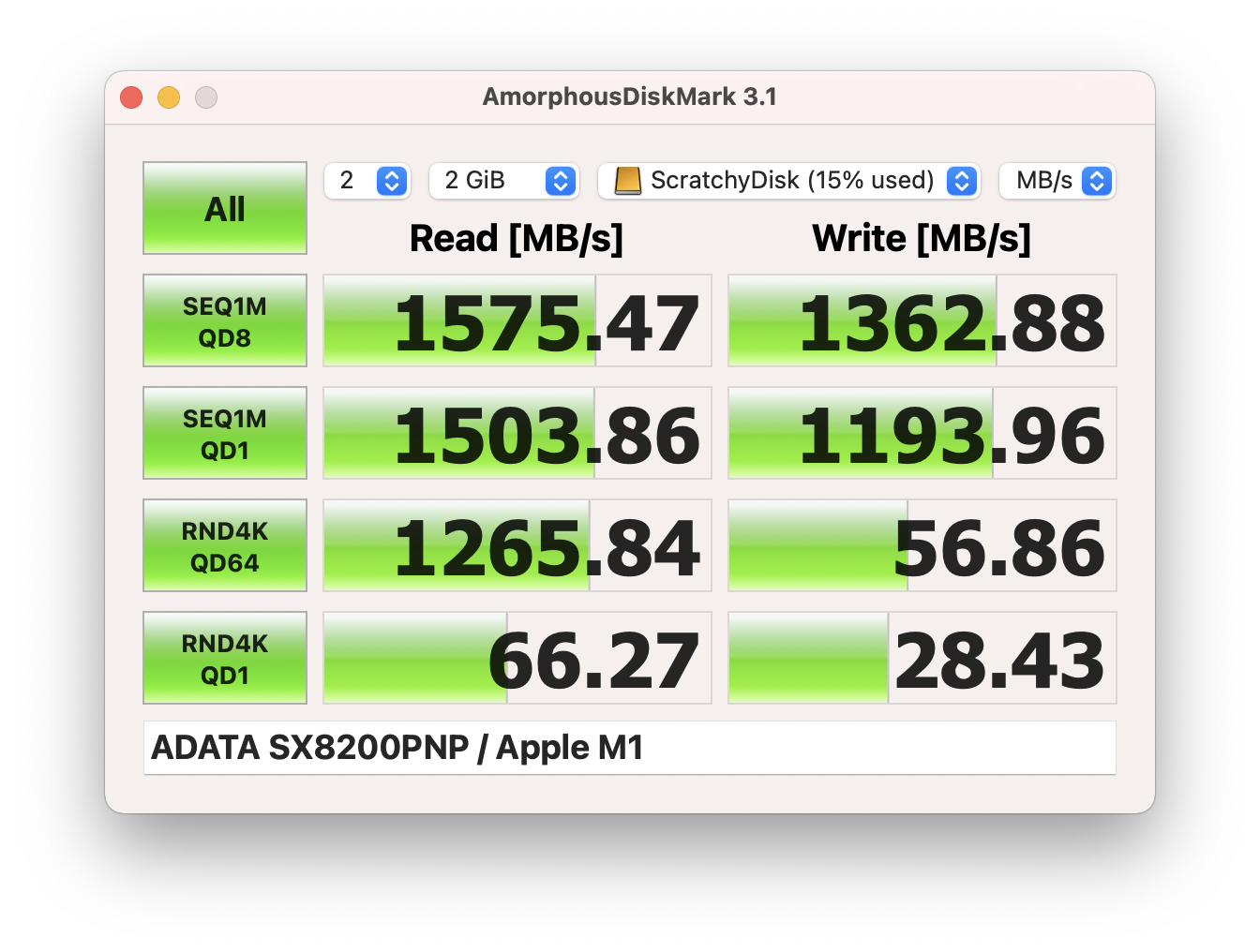
To briefly re-cap my last post, I recently upgraded my home cinema speakers to the new MK Sound M-Series:
- 3 x M&K Sound M70 – Left/Centre/Right
- 1 x M&K Sound M40T – Surround Pair
- 1 x M&K Sound V10 – Subwoofer
So as promised, here is my “review” 1 of the system.
Unboxing
M&K speakers are packaged very well in polystyrene. There is nothing much more to say about the unboxing, other than what’s inside the boxes.

The last thing I expected to find when opening a speaker box was a pair of gloves. That’s right, M&K speakers all come with a pair of white butlers gloves! This is presumably to encourage handling them with care and ensuring you do not get any fingerprints on the perfect finish. I would say to take extra care if you do use the gloves, as the speakers are very slippery in your hand with them on.
Aesthetics
These speakers are absolutely brilliantly made. They are completely solid with no seams or joins in the cabinet, complete with rounded edges and corners. It feels akin to the unibody MacBook Pro.
When I say they completely smooth – they are. There aren’t even mounting holes for the speaker grille, but guess what? You don’t need any! Bring the grille into position and it snaps into place using magnets. Very Apple-esque.
Note, this is only true of the M-Series so perhaps could be a new feature. The V10 sub still has mounting holes for the grille.
Mounting
The M-Series is designed to be wall-mounted and, as can be seen from the manufacturer’s pictures, there are keyhole fixings on the rear for vertical or horizontal positioning. Each came with a set of screws and rawlplugs, however I chose to use my own, heavier-duty ones to ensure a safe fixing in plasterboard.
Mounting the surrounds on the ceiling was a little more tricky as, again, they’re designed to be wall-mounted. In the end, I found an appropriate set of little speaker mounts for a great price.
Sanus tilt and swivel universal speaker mount white (available at Screwfix and Richer Sounds). Note, they are sold as a pair – you don’t need to buy two!
I had to drill holes in them to align with the holes in the M40T, which was only possible on the diagonal. Still, very straightforward and then just popped in some longer M4 screws.

Note, I only left the keyhole fixing in to act as a spacer because the screws I had lying around with the correct thread were too long. I don’t mind – it’s a good way not to lose them for the event I want to mount them on a wall one day!
Setup
The M-Series doesn’t have anything to set-up – there are no controls on them. The V-10 subwoofer on the other-hand, has a 16 page manual (available as a download from the MK Sound website).
To summarise, set the crossover to bypass, phase to zero and volume to 12 o’clock. One other note on the V-10 is that is didn’t come with a UK power-cord (just US and EU). This didn’t bother me as I had already pre-wired an extension for the sub-location, but who doesn’t have a spare IEC lead lying around, anyway?
Then it was a simple case of (re-)auto-calibrating my AV receiver. This is a straightforward process of measuring the sound with a provided microphone from the listening position (and several around it).
The other adjustments I made were:
- Set the subwoofer mode to LFE + main
The low range signal of all channels is added to the LFE signal output from the subwoofer
- Increase and unify the crossover to 110Hz
(was calibrated at 90-100Hz)
- Increase the LPF to 120Hz
Set LFE signal playback range. Changes the playback frequency (low pass filter point) of the subwoofer.
- Turn the sub volume control up slightly so the base sounded more in-balance.
Sound
It didn’t take long to be blown-away with the sound quality. As soon as you plug in these speakers, they just work. No faffing.
The speakers are incredibly clear and immersive. With my pervious setup, I was using options like “Dolby Surround Upmix”, “Center Spread” and increased “Dialog Level”. None of these are needed (nor improve) the MK loudspeakers.
Across the front, the sound is incredibly “complete”. There are no missing areas and there is a very smooth transition between locations. You can hear every detail without increasing the volume which (perhaps negatively) shows up the imperfections in recordings and bad mixes.
Speaking of smooth transitions, the subwoofer blends seamlessly into the rest of the sound. There is no “this is where the satellites end and this is where the subwoofer starts”. With my previous system, it was very obvious when the sub was turned off, not only because the satellites were weaker, but because the base was very isolated. Complete opposite with the M&K package. The base is powerful when called for (you can really feel it) and supports the satellites for great depth the rest of the time.
As for the rears, the tripole M40Ts fit into a 5.1 system very nicely. They make you feel as though you’re “inside” the sound, without drawing attention to where the speakers are. When there are direct sound effects at the back – you notice, other than that – they just enhance immersion.
Overall
From the unboxing and installation, through to the listening experience and looking at them every day, I am completely satisfied with my M-Series 5.1 package choice. I was looking for an accurate sound that fills the room for a respectable budget. All of my expectations have been met and some surpassed.
For what I got, and what I paid, I couldn’t ask for more. Having said that, after using the system for a month I am perhaps more aware of the limitations of a 5.1 system. While the front is very “full” and the surrounds create immersion, the transition between them and the elevated position of the rears highlight a place for additional speakers (think 7.1, Atmos, etc).
Given this set-up is in my open-plan living space and I have a distinct lack of lossless and multi-channel (> 6) sources to start with, I shall restraint from going further down that path for the moment.
However, one thing I must do is upgrade my AVR to do the M&K speakers justice. Not only for cleaner amplification and power, but I’m sure I would benefit from advanced room correction. One for later in the year when I have the time and budget…
1 “review” I use quotation marks because I am not really qualified to review speakers – I’m not an expert, I do not have the correct room environment / AVR / measuring equipment to be scientific, and I have not listened to anything comparable recently. The speakers were bought entirely on recommendation and I most likely have a form of post-purchase confirmation bias.